中国高分辨率土壤数据集发展与更新
实验室团队成员在七年前发布了一套综合性中国土壤数据集(China Dataset of Soil Properties for Land Surface Modeling,CDSL),该数据集在近年的陆面过程及其它地学研究和应用中发挥了重要作用。然而,随着时间推移,其自身存在的一些问题和不足日渐凸显。新的可获取的站点观测(土壤剖面)、制图技术的新发展、对土壤属性图空间分辨率和准确度的更高需求等使得新版本CDSL2的发展成为一项可行并具重要意义的工作。在站点观测方面,在CDSL的全国第二次土壤普查的8979个土壤剖面基础上,增加了世界土壤信息服务数据库、全国第一次土壤普查数据、土壤标本数据和一些区域研究中产生的站点观测等。在空间预测模型方面,将采用基于百余个土壤协变量大数据的机器学习模型。
本课题对站点的土地利用信息进行整理,分为农业用地、裸地、林地和草地几类,然后分析了土地利用对土壤属性的影响。结果发现,土壤粗颗粒(砾石和砂粒)含量在草地和林地较低,而在农业用地上最低,裸土最高,而细颗粒的粘粒恰恰相反;有机质、全氮、阳离子含量和有效氮呈献较一致的规律,含量从高到底依次为林地、草地、农业用地和裸土,即植被越茂密越高;容重和pH值得规律跟以上四个属性相反,这主要是因为有机质含量高,则容重较低,pH值较小;对于有效磷,农业用地和裸地含量较高,而林地和草地较低;对于全磷、全钾和有效钾,各种土地利用类型的区别不大。
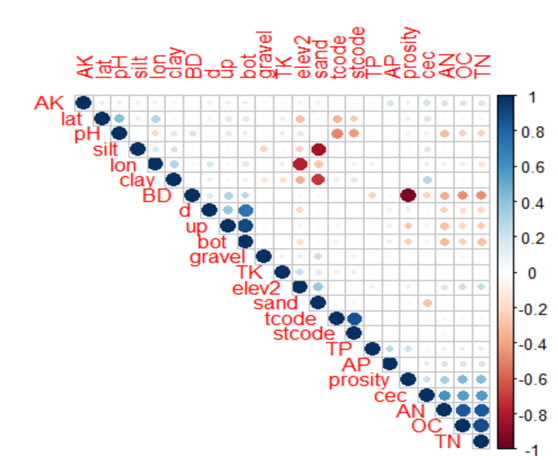
本研究分析了各个土壤属性之间的相关关系,见图3.1。结果表明大部分属性的相关关系较弱,相关较高的有砂粒和粉粒、砂粒和粘粒、容重和孔隙度、有效氮和有机质、有效氮和全氮、有机质和全氮。利用变量间的相关关系可以针对数据较少的土壤属性建立土壤转换函数,从而补全数据。基于随机森立模型建立的土壤转换函数对不同属性的有效性区别较大,解释方差超过50%的为有效氮、阳离子含量、全钾、砾石和容重,而孔隙度、有效磷和有效钾的模型则较差。
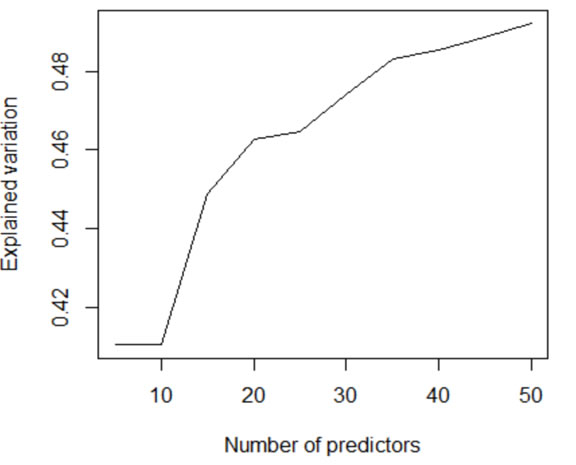
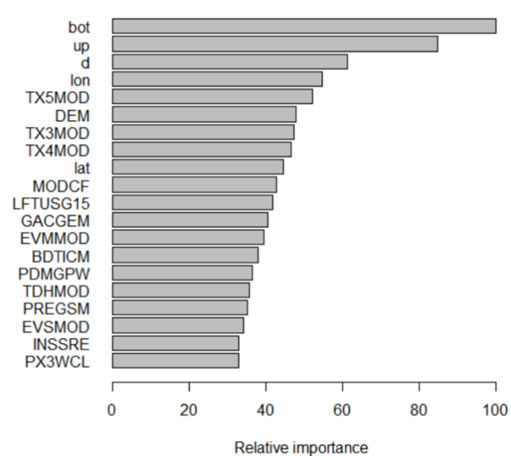
本研究基于随机森林模型建立了初步的空间预测模型,在不对误差进行校正和不进行参数调整的情况下,对有机质建立的模型的解释方差能达到51%。考虑到特征个数过多会造成模型复杂度提高和过拟合,适当降低了特征个数。图3.2表明特征个数在30个时,模型表现已经接近最优,解释方差为47.5%。因此,将此模型设定为默认模型,开展后续的不同误差或因素对模型表现得影响。图3展示了不同特征对模型性能的相对重要性。影响土壤属性的最重要因子时其所处的土壤深度,其次还有经度、地表温度、高程、纬度、云覆盖、地貌类别等。
本研究分析了站点位置误差对空间预测的直接影响。位置误差大会使模型的解释方差从53%下降到47%左右。但实际建模中不可能仅用高位置精度的站点,因为这些站点的数目非常有限,仅占所有数据的五分之一。因此需要对站点位置进行校正。
此外,还分析了站点高程位置误差、土地利用、土壤类别对空间预测的影响。站点的高程误差大部分在100米以内,相对误差大部分在50%以内。用精确的站点高程建立的模型相比默认模型的解释方差从47.5%提高供到49.6%;土地利用信息的加入则使模型表现提高到49.4%;土类和亚类信息的加入分别使模型表现提高到49.2%,土属信息因较少,加入后并未使模型显著变好;而将土类、亚类、站点高程和土地利用信息同时加入后,模型表现最终提高到53.7%。
